배경
메모리는 현대 컴퓨터 시스템 동작의 주축이다. 메모리는 각자의 주소를 가진 대용량의 바이트(byte) 배열과도 같다.
CPU는 메모리로부터 Program counter에 대응하는 연산을 fetch하며,
이 연산들은 특정 메모리 주소에 대한 추가적인 load, store가 필요할 수 있다.
전형적인 연산-실행 순환 과정(Instruction-Execution Cycle)은 다음과 같다.
1. 연산이 메모리로부터 fetch된다.
2. 해당 연산은 decode되어 다른 피연산자를 메모리로부터 fetch할 수도 있다.
3. 연산이 피연산자에 대해 실행되면, 결과는 다시 메모리에 저장(store)된다.
메모리 단위는 그저 메모리 주소들의 연속일 뿐이며, 그 주소들이 어떻게 생성되었는지나 어떻게 사용되는지는 모른다.
따라서 우리는 프로그램이 메모리 주소를 어떻게 생성하는지에 관심을 가질 필요가 없다.
단지 실행되는 프로그램에 의해 생성된 메모리 주소에만 신경쓰면 된다.
이 단원에서는 메모리를 관리하는 다양한 기법에 대해 알아본다.
Basic Hardware
CPU는 메인 메모리와 프로세서 자체에 내장된 레지스터에만 직접 접근할 수 있다.
메모리 주소를 인자로 하는 기계적 연산이 존재하지만, 디스크 주소를 인자로 하는 연산은 없다.
따라서, 실행되는 모든 연산들과 연산에 사용되는 데이터들은 직접 접근 가능한 메모리 영역에 존재해야 한다.
만약 이 영역 밖의 데이터를 사용해야 한다면, CPU가 접근하기 전에 데이터를 직접 접근 가능한 메모리 영역에 미리 옮겨놔야 한다.
캐시 (Cache)
CPU에 내장된 레지스터들은 일반적으로 1 CPU clock 내에 접근 가능하다.
하지만 메모리 접근을 완료하는 것은 많은 CPU clock을 필요로 할 수 있다.
이러한 상황에서 필요한 데이터가 없는 프로세서들은 실행 중인 연산을 완료할 수 없기 때문에, 일반적으로 정지(stall)한다.
하지만 메모리 접근의 빈도가 매우 높기 때문에, 어느 순간 정지 시간을 더 이상 견딜 수 없게 될 것이다.
해결책은 CPU와 메모리 사이에 속도가 빠른 메모리(fast memory) 하나를 추가하는 것이다.
이를 Cache라 한다.
Base ans Limit
물리적 메모리에 접근하는 속도 뿐만 아니라, 사용자 프로세스가 운영체제에 접근하는 것과 사용자 프로세스를 상호간에 보호하는 것 또한 고려해야 한다. 이 보호는 반드시 하드웨어에 의해 제공되어야 한다.
우선 각 프로세스가 서로 분리된 메모리 공간을 사용하도록 한다. 이를 통해 우리는 프로세스가 접근할 수 있는 유효한(legal) 메모리 주소의 범위를 정할 수 있고, 프로세스는 이 legal 메모리 주소만 접근하도록 할 수 있다.
이는 Base, Limit이라는 두 레지스터를 통해 제공할 수 있다.
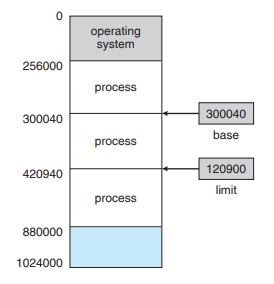
Base 레지스터는 legal 메모리 주소의 시작 주소(가장 작은 주소값)를 정하고, Limit 레지스터는 legal 메모리 주소의 범위를 저장한다.
그림에서 base = 300040, limit = 120900이므로 legal 메모리 주소 범위는 300040 ~ 420940 (base + limit) 이다.

사용자 모드에서 실행 중인 프로그램의 운영체제 메모리나 다른 사용자의 메모리에 대한 모든 접근 시도는 운영체제에 Trap을 발생시켜, Fatal Error로 간주된다. 이러한 방법은 사용자 프로그램이 실수 또는 고의에 의해 허가되지 않은 메모리 영역의 코드나 데이터 구조를 수정할 수 없도록 한다.
Base, Limit 레지스터들은 운영체제의 전용 연산에 의해서만 적재(load)된다. 이 전용 연산들은 커널 모드에서만 동작하고 또한 운영체제만이 커널 모드를 실행할 수 있기 때문에, 오직 운영체제만이 이 레지스터들의 값을 변경할 수 있다. 따라서 사용자 프로그램이 레지스터들의 값을 변경할 수 없도록 한다.
Address Binding
보통 프로그램은 실행 가능한 이진 파일(binary file)의 형태로 디스크에 저장되어 있다. 프로그램은 실행되기 위해 프로세스 내의 메모리로 옮겨져야만 한다.
사용하는 메모리 관리 기법에 따라 다르지만 프로세스는 실행 동안 디스크와 메모리 사이를 옮겨 다닐 수도 있다. 이 때실행을 위해 메모리로 옮겨지는 것을 기다리는 프로세스들은 Input Queue에서 대기하게 된다.
일반적인 과정은 다음과 같다.
- Input Queue에서 프로세스 하나를 선택해 그 프로세스를 메모리에 적재한다.
- 프로세스가 실행되면, 메모리의 연산과 데이터들에 접근하게 된다.
- 이후 프로세스가 종료되면, 그 프로세스가 사용하던 메모리 영역은 다시 사용 가능한 메모리 영역이 된다.
대부분의 시스템들은 사용자 프로세스가 물리적 메모리의 어떤 부분을 차지해도 상관없도록 허용한다. 따라서 메모리의 시작 주소가 0번이라고 해서 반드시 사용자 프로세스의 첫 주소가 0번일 필요는 없다.
사용자 프로그램은 실행되기까지 몇 가지 단계를 밟게 되는데, 이 과정 중에서 주소들은 다양한 방법으로 표현된다.
프로그램의 주소는 일반적으로 Symbolic 주소(이를테면 "count"와 같은 변수의 형태)인데, 컴파일러는 이러한 Symbolic 주소를 "이 모듈의 시작 주소로부터 14바이트" 라는 실제 주소로 bind한다.
메모리 주소의 binding 과정은 다음과 같다.
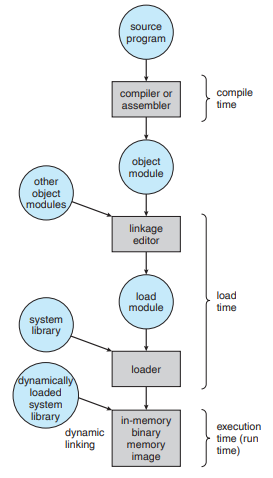
컴파일 시간(Compile time) : 만약 프로세스가 메모리에서 차지할 영역을 컴파일 시간에 알고 있다면, Absolute Code가 생성될 수 있다. 예시로, 만약 사용자의 프로세스가 R이라는 주소부터 메모리를 차지할 것을 알고 있다면, 생성된 컴파일러 코드는 R 위의 주소만 사용하도록 한다. 만약 시작 주소가 변경된다면 코드를 재컴파일해야 한다.
적재 시간(Load time) : 만약 컴파일 시간에서 프로세스가 차지할 메모리를 알 수 없다면, 컴파일러는 반드시 Relocatable Code를 생성한다. 이 경우엔 적재 시간동안 binding은 연기되며, 시작 주소가 변경된다면 사용자의 코드만 다시 재적재하면 된다.
실행 시간(Execution time) : 만약 프로세스가 실행 동안 여러 메모리 영역을 옮겨다닌다면, 실행 시간동안(runtime) binding은 연기된다. 대부분의 운영체제는 이 방법을 사용한다.
논리적 주소와 물리적 주소 (Logical & Physical Address)
논리적 주소(Logical Address) : CPU에 의해 생성되는 주소를 일반적으로 논리적 주소라 한다.
물리적 주소(Physical Address) : 메모리 주소 레지스터에 표시되는 주소를 물리적 주소라 한다.
컴파일 시간 및 적재 시간의 Address Binding은 동일한 논리적, 물리적 주소를 생성하지만, 실행 시간의 Address Binding은 서로 다른 논리적, 물리적 주소를 생성한다.
이 경우, 우리는 논리적 주소를 일반적으로 가상 주소(Virtual Address)라 한다. (이후에도 같은 것으로 취급한다.)
프로그램에 의해 생성된 모든 논리적 주소들의 집합을 논리적 주소 공간(Logical Address Space)라 하고, 마찬가지로 모든 물리적 주소들의 집합을 물리적 주소 공간(Physical Address Space)이라 한다.
MMU (Memory-Management Unit)
실행 시간(Run-time)동안 가상 주소를 물리적 주소로 변환해주는 하드웨어이다.
MMU를 사용해 주소를 변환하는 방법은 위의 Base 레지스터를 일반화하여 단순하게 표현할 수 있다.
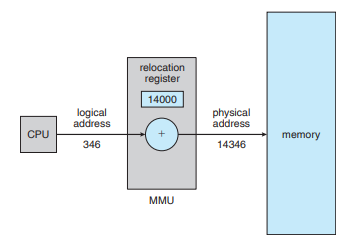
이 때는 Base Register를 Relocation Register라 부른다.
사용자 프로세스에 의해 생성되는 모든 주소들에 Relocation 레지스터의 값을 더해 실제 메모리 주소를 구한다.
그림에서 사용자 프로그램은 절대 실제 메모리 주소를 확인할 수 없다. 단지 346의 포인터를 생성하여 사용할 뿐이다. 사용자 프로그램에서 메모리는 346이라는 논리적 주소를 통해서만 사용된다.
논리적 주소가 0 ~ max라면, 물리적 주소는 R ~ R + max의 값을 갖게 되는 것이다. (R은 Base Register의 값이다.)
논리적 주소는 반드시 사용되기 전에 물리적 주소로 변환되어야 한다.
Dynamic Loading
지금까지 설명한 내용에서는 프로세스가 실행되기 위해서는 반드시 프로그램과 데이터 전체가 물리적 메모리에 존재해야 했다. 따라서 물리적 메모리의 크기에 따라 프로세스의 크기도 제한된다.
메모리 공간의 사용성을 높이기 위해, Dynamic Loading을 사용할 수 있다. Dynamic Loading은 호출되기 전까지 프로그램을 적재하지 않는 것으로, 필요할 때마다 그때그때 적재된다.
Dynamic Linking
Static Linking은 시스템 언어 라이브러리가 다른 모듈과 같이 취급되며, 로더(Loader)에 의해 binary program image로 취합된다.
이에 반해 Dynamic Linking은 Dynamic Loading과 마찬가지로 실행 시간까지 linking을 미룬다.
Dynamic Linking에서는 각 라이브러리 참조 루틴에 Stub 이라는 작은 코드가 포함되는데, Stub이 실행되면 필요한 루틴이 이미 메모리에 있는지 확인한다. 만약 아니라면, 프로그램은 그 루틴을 메모리에 적재한다.
※ 본 게시글은 『Operating System Concepts』 를 참고하여 작성되었습니다.
'운영체제' 카테고리의 다른 글
| [OS/운영체제] 페이징 (Paging) - (1) (0) | 2020.11.13 |
|---|---|
| [OS/운영체제] 메인 메모리 (Main Memory) - (2) (0) | 2020.11.12 |
| [OS/운영체제] 데드락, 교착 상태 (Deadlock) (0) | 2020.11.12 |
| [OS/운영체제] 프로세스 동기화 (Process Synchronization) - (2) (0) | 2020.11.10 |
| [OS/운영체제] 프로세스 동기화 (Process Synchronization) - (1) (0) | 2020.11.10 |