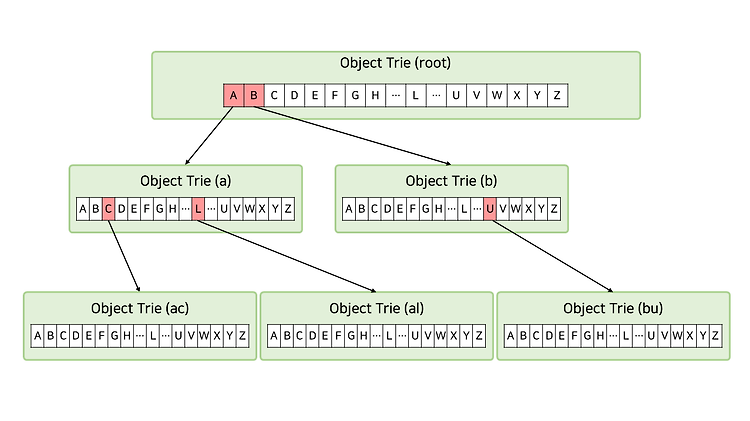
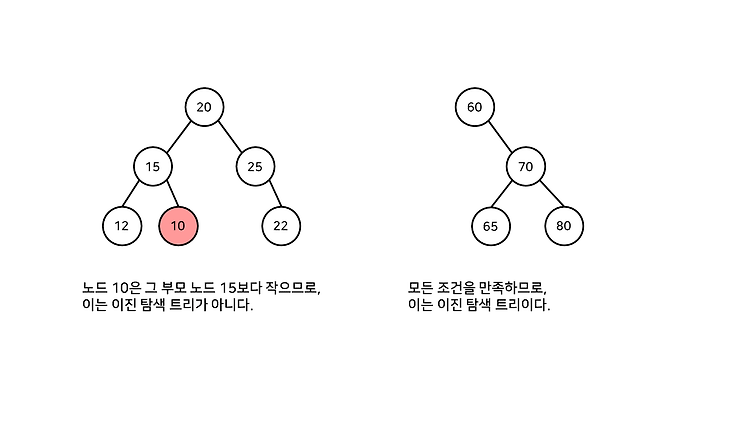
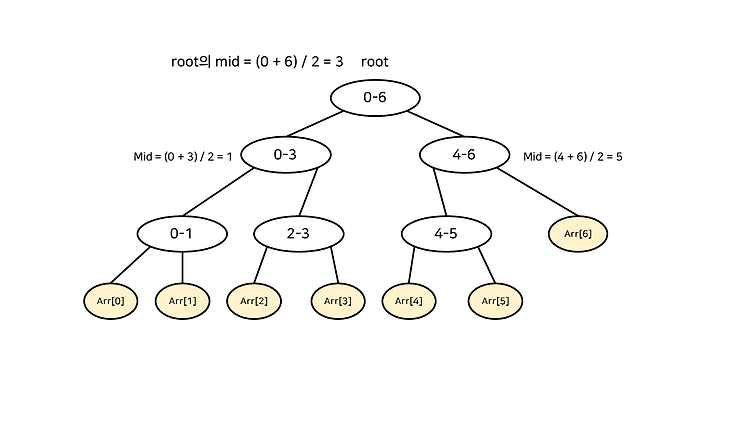
단어 찾기 사전에서 "Algorithm" 이란 단어를 찾는 상황을 가정해보자. 사전에서 단어를 찾는 방법은 여러 가지가 있을 것이다. ① 단순 탐색 : 사전의 처음부터 Algorithm이 나올 때까지 모든 단어를 확인 가장 확실하고 구현하기 쉬운 방법이지만, 찾고자 하는 단어가 사전의 어느 위치에 있냐에 따라 걸리는 시간이 천차만별일 것이다. 따라서 모든 경우에 대해 그다지 좋은 효율을 갖고 있다곤 할 수 없을 것이다. ② 이분 탐색 : 사전의 절반 지점의 단어를 확인 사전의 처음부터 끝까지 모든 단어들 중 딱 절반 지점의 단어를 확인한다. 이 절반 지점을 mid라 하자. 이 때 확인된 단어가 찾고자 하는 단어보다 사전 순으로 앞서면, 다음 탐색 범위는 mid부터 사전의 끝이 될 것이다. 또한 앞서지 않..